|
|
|
Greetings. If the public brouhaha over the revelations here regarding Rogers' testing of third-party Web pages interception and modification (Google Hijacked -- Major ISP to Intercept and Modify Web Pages -- and linked updates) led you to believe that they'd be backing off from these plans, you'd be sadly mistaken. Word is that Rogers is still moving forward towards full-scale deployment of the system, even though they feel that it would have been a simpler sell to the public if not for the "uncontrolled" manner in which we all learned of the Internet intrusions that the ISP has planned. They still firmly believe that their scheme is sound. Their only really significant mistake -- Rogers supposedly now thinks -- was that in retrospect, their slapping the Yahoo! logo onto test Rogers messages being inserted onto other parties' Web pages was a sure way to attract unwanted early attention from, for example, Google. Oops! But Rogers is nothing if not resolute, and they've reportedly got some propaganda tricks up their sleeve to try convince their subscribers -- and the world -- that inserting messages and perhaps much more into other people's Web page data is just a grand idea. Rogers after all has strong roots in the cable TV industry, and apparently may argue that their inserting messages into private Internet connections is no worse than rolling a severe weather warning crawl at the bottom of TV channels. And in an attempt to bring a "third rail" issue into the mix, "Amber Alert" (missing children) messages might be inserted as well -- allowing Rogers to argue that anyone opposed to *that* sort of Internet insertion must obviously be some sort of antisocial, uncaring pervert -- or worse. But Rogers also reportedly has not ruled out using this same insertion technology for running their own ads on unaffiliated Web pages, which is of course the primary application that the equipment vendor, who is so heavily involved, publicly and loudly promotes. This all tends to brand the whole of Rogers' arguments regarding this entire topic as merely faux public spiritedness at best. Don't make a mistake about this. 2007 has been the year that the smiling public relations faces of the big ISPS have begun to reveal some sharp fangs indeed. ISPs have been playing a "shell game" with subscribers for years, promising "unlimited" Internet services over grossly under-provisioned network facilities, based on increasingly false assumptions about how subscribers will actually be using their Internet connections. As users absorb increasing bandwidth for a range of popular (and, I might note, completely legal) new applications, ISPs have invoked vague or oblique clauses in Terms of Service agreements, in an attempt to rein in those customers that the ISPs have arbitrarily defined as "abusers" of one sort or another. As ISPs move away from being the "mere" conveyors of data toward a potentially much more lucrative and intrusive role as the arbiters of everything that we do (unencrypted, anyway) on the Internet, the warning signs during 2007 were obvious for everyone to see. We saw AT&T announce plans to monitor their network for "pirated materials" -- definitions and means still unclear -- and calls from some in the entertainment industry for all ISPs to do the same. Comcast got caught lying about directly interfering with file sharing protocols by forging data packets, and of course we have this current Rogers story. The handwriting is very much on the wall. 2008 is likely to be a watershed year for arguments regarding network neutrality, and in the determination of the Internet's future directions and fundamental operating philosophy. Whether or not ISPs will be permitted to remake the Internet to match their own often warped and selfish vision hangs in the balance. However, the ultimate decisions about the future of the Net -- if we're up to taking a stand with our wallets and laws -- are actually ours to make as Internet users (both consumers and businesses) and as legislators who create the ground rules under which we all must play -- and pay. Sitting on our hands any longer is simply not a viable option. Let's use the next year to help make sure that the Internet is and remains open, transparent, competitive, and nondiscriminatory -- in the best interests of all its users. And all the best to you and yours for 2008! --Lauren-- |
|
Greetings. After initially suggesting to me that there was nothing at all wrong with their display of addresses for unlisted telephone numbers on their services inquiry Web site, Acceller -- in a communication to Wired News -- has now promised to alter their system to end this privacy-invasive practice. Acceller appears to be blaming their data vendor for never differentiating between listed and unlisted numbers, so Acceller says that they simply displayed whatever data was provided to them -- an interesting policy, to say the least. In any case, the underlying issue in this whole affair really relates to the lax rules associated with the handling of such data in the first place, and no doubt there will be plenty more to discuss about that in the future. For now -- assuming that Acceller follows through on their commitment in a timely manner -- all's well that ends well, it appears. Merry Christmas, everyone. Take care. --Lauren-- |
|
Update Bulletin (December 21, 2007 1740 PST): Acceller Promises to Close Unlisted Number Address Exploit Greetings. After due consideration, some expert advice, and since the firm involved obviously feels that they're not doing anything wrong (will everyone else agree?), I've decided to release the details of the unlisted number to address lookup "exploit" I outlined in Psst! Wanna Know the Street Address for an Unlisted Number? -- please see that entry for the background on this situation. This "exploit" is still up and running as of a few minutes ago. As noted previously, this technique is extremely successful at revealing the street addresses for U.S. landline (non-mobile) telephone numbers, including those aforementioned unlisted numbers. The returned information isn't 100% accurate for all queries and some numbers are missing -- I suspect stale data in certain situations -- but it's very "good" overall. Also, the full text of a response I received from the company's (apparent) public relations firm is available for your perusal and amusement. Calling this procedure an "exploit" is actually a misnomer as you'll see, since it's simple and direct to access once you know where it lives -- and even that is unfortunately relatively obvious, so it seems very likely that it's already being used for "unintended" purposes. My hope is that broader knowledge of this matter may lead to a more rapid resolution of the situation, since the firm chose not to limit this data after I called their attention to the privacy issues involved. As you probably know, various large cable television and other service firms (e.g. Time Warner, Comcast, etc.) offer an array of Web-based offers via their Web sites. The most typical means for a new customer to query these sites about available offers at their location is via their phone number. And as it turns out, a major provider of back-end database and related operations provides various functional aspects of many related Web sites. Enter a phone number at the Time Warner offers site, for example, and it's likely to actually be processed by this back-end service (sometimes in a quite obvious manner). It is also apparently possible to make similar queries via voice calls to a toll-free number at the back-end services firm's call center, but I have not explored the non-Web aspects of this operation in detail. Rather than worry about the cable firms in this example (though we could go through their sites as well when they link to this company) we might as well go directly to the back-end operation that's providing the information, since their own site apparently gives access to exactly the same data. Here we go ... The company under discussion is Acceller, Inc., and you can visit their services access page at: In the upper right-hand corner of the page, you'll find a "Search For Offers" form where a phone number may be entered -- then click "Compare Offers Now" -- it's that simple. (Note: You may need to have cookies enabled for this to work, and Internet Explorer may perform better than other browsers in some cases for these queries.) Enter a phone number, watch the bouncing ball for 10 seconds or so, and then you stand an excellent chance of seeing a street address revealed for U.S. non-mobile numbers (along with the various service offerings available at that address, of course). The "geniuses" who programmed that site probably won't be getting any job offers from Google anytime soon. The implementation error is serious and obvious. The proper procedure to avoid revealing private information about unlisted numbers would be to have the user enter their address -- not reveal it from the database based on phone number -- and then verify it yes or no against the database (even this suggested technique has some privacy issues, but they are relatively less serious and could be minimized in various ways). By taking the "helpful shortcut" of revealing the address, the system is putting at risk -- for free and unlimited access by anyone at any time -- the private address information for unlisted numbers. I'm afraid that's really all there is to it. Simple, clean, and neat, to be sure. If you've been paying your local phone company every month for an unlisted number and are upset by this situation, I urge you to contact your telephone company, Acceller, and -- who knows? -- perhaps even your legislative representatives might be intrigued, among other persons and groups. Unfortunately, this isn't the sort of Christmas present that most people probably would wish for. But it appears to be Acceller that's doing all of the ho-ho-hoing. --Lauren-- Update (December 21, 2007): As of 0900 PST this morning, the exploit is still up and running. A few additional notes: First, if the number you enter is not in the database, you may be asked to enter your address manually -- under normal conditions for numbers that are in the database this step will not take place and the address will be presented to you based solely on the phone number. It still appears that my earlier estimate -- that about 80% or so of landline numbers do show up with correct addresses in the database -- is pretty close to the mark, but as I pointed out above there are missing numbers, and inaccurate data for some numbers. It's reported that persons who have their billing address set to a P.O. box may get that address returned rather than a street address, which seems logical enough. Finally for now, I've had a report from someone who tested a number deep in an inbound-only rotary hunt group -- a number that would never have been listed of course -- and had the address come up correctly. This tends to point strongly toward the ILEC (phone company) as the data source in that case at least. --LW-- Update Bulletin (December 21, 2007 1740 PST): Acceller Promises to Close Unlisted Number Address Exploit |
|
Greetings. In a recent blog entry, I noted the existence of a site (which is interconnected with many other sites, as it happens) that allows for the direct and simple entry of landline telephone numbers, and in most cases will happily return the street addresses for those numbers -- even if the numbers are unlisted. It seems to return correct addresses about 80% or so of the time, perhaps more. Already, a number of persons who have unlisted numbers due to various security concerns have expressed alarm over this situation. After all, phone numbers are much more easily obtained (caller ID, business transactions, etc.) than associated street addresses (at least until now), and just because someone provides a phone number doesn't mean that they want to have folks showing up at their front door or barraging them with physical mail. The interesting questions associated with this situation include where is the unlisted number data coming from -- unlisted numbers are supposed to be held to a higher security and usage standard -- that's why people typically have to pay extra every month to be unlisted in the U.S. Possible sources are the telco databases and third party data miners, or some combination of the two (several phone numbers I've tested that are in the site's database have never been used in the course of business, so a telephone company source seems more likely in those cases). By offering addresses for numbers rather than requiring the customer to enter an address and then confirming it, the company involved has made a fundamental data privacy implementation error of a sort I wouldn't expect from a first year programming student. I have now received a reply back from the company's PR firm, which I will characterize as "we're not doing anything wrong and we're not going to change anything so tough luck and have a nice day." I suspect that there are millions of people with unlisted phone numbers who are as concerned as I am about the easy availability of their street addresses on an open and free Web site. I'm in something of a quandary as to what to do next. On the other hand, I have no desire to see unlisted number addresses revealed en masse, which would likely be the immediate result if I identified the specific site(s) involved. Suggestions as to what to do next are invited. I want to move on this one way or another as soon as possible. Thanks. --Lauren-- Blog Update (December 20, 2007): Details of Unlisted Number Address "Exploit" Revealed |
|
Greetings. It's true enough that Hollywood permeates everywhere here in L.A. these days. That goes for everything from major productions in the walled studio complexes (which have always struck me as something like military bases both inside and out), to the porn producer who rents out his home for "adult entertainment" shoots two doors down from my house here in the West San Fernando "Porn Production Capital of the World" Valley. The red doorknob tags that warn nearby residents of imminent location filming are pretty much ubiquitous, as are the yellow signs replete with arrows and often odd names (which all must seem fairly mysterious to visitors) that pop up frequently on telephone poles pointing the way to shoots for talent and crews. So the Writers Guild of America (WGA) strike that began November 5th isn't just an academic issue here in town. You're likely to run into striking writers in guild t-shirts at the supermarket, and even more likely to stumble across "below the line" workers (all manner of "behind the camera" staff and crew) who are being drastically affected -- everywhere you go. While it's true that some industry writers are very highly paid, it's also a fact that many earn what can only be considered to be relatively modest incomes by most any standard, and that's when they have work. Below the line, keeping the rent paid is even more problematic. The reason I bring this all up is that the Internet is the front and center cause for all of this upheaval. By and large, the strike is about new media -- the concerns of the WGA that entertainment industry contracts are written in a way that largely lock them out of Internet-related income streams in a manner reminiscent of the lopsided allocations of DVD proceeds. As conventional media slowly fades and "new media" moves in to take its place, the creative element in Hollywood sees itself being shafted by the same entrenched corporate entertainment forces that we techies complain about so much in relation to DMCA abuses and the like. The technologies we're creating are right in the middle of all this, and affecting a great many real lives in this respect -- both writers and non-writers -- in complex ways. That's not to say there aren't two sides to the story. A counter-argument is that the income streams from new media are relatively tiny at this point, and that's true. But the history of Hollywood throughout its entire existence has been a parade of creative "trickle down" accounting, and the WGA is understandably trying to avoid having its members burned in the long term as major technology realignments are changing the entertainment industry landscape. So the next time you see a story about the strike, please remember that it isn't all about the super rich in the Malibu Colony, but also about a lot of ordinary folks who are just as much prisoners of the system as the rest of us, and that our technologies are in many ways -- as usual -- the name of the game. --Lauren-- |
|
Greetings. A must read New York Times article on the Bush Administration's push for vast international and domestic spying on telephone and e-mail transactional data, plus "vacuum cleaner" phone call and data surveillance projects, should alarm everyone who cares the least bit about their privacy. Of particular note are imminent Congressional votes to determine if telecom firms will be granted immunity for spying abuses if they participate in these clandestine government efforts. This proposed immunity appears to be absolutely key to the firms' open-arms, largely unquestioning participation, and for that very reason should not be granted by Congress. Here's why in a nutshell. If the activities that the government wishes to pursue in this area are justifiable and legal, then the telecoms should have nothing to worry about regarding their cooperation. On the other hand, if these government surveillance projects are illegal, it is not in the telecom firms' best interests to become involved under any circumstances, given the potential risks of consumer backlash and retroactive legal changes when such cooperation and unfortunately likely abuses are ultimately exposed, even if immunity is granted now. It can be argued that these firms have no sure way to know a priori whether or not such government inspired activities are legal today or will be considered to be legal in the future. This is true -- but frankly, my response is "Tough luck, that's the cost of doing business, and if you have any concerns that something you're being asked to do is illegal, then perhaps you should err on the side of caution and refuse to play along." The lack of immunity for telecom company surveillance abuses is virtually the only friction left in the system that helps to prevent a wholesale slide towards utterly pervasive communications spying. If the government can successfully make its case that requested activities are legal, so be it. Otherwise, the telecom firms should be required to take their chances and make their decisions -- relating to government communications surveillance programs -- with the same litigation potential as exists with their other corporate operational decisions. NO to telecom immunity! --Lauren-- |
|
Greetings. A number of folks have been sending me copies of Google's blogged preliminary announcement regarding the early testing of their knol project, perhaps accurate to describe as something like an attributed online encyclopedia with broad user comment and contribution capabilities. The key word here is attributed. While community submitted questions, comments, additional material, and the like would presumably not be subject to rigorous authorship identifications, the foundational article on each topic will reportedly be fully attributed to specific identified authors. This may be something of a "hallelujah" moment, for knowledge of who wrote an entry presented as authoritative can be paramount to the reader's ability to judge the veracity and value of the text. I've long felt that any author who wants to be taken seriously should strongly desire to be attributed in all but a very narrow set of circumstances (e.g. anonymity can be important in "whistle-blower" situations and the like). The knol announcement is being widely characterized as a direct attack on Wikipedia (even I framed it in "vs." terms in the title of this piece), but I'm unconvinced this is a completely accurate characterization. While I certainly use Wikipedia in some situations -- for quick technical information lookups or movie synopsis details it's very handy -- I have long been concerned about the easy mutability of its articles combined typically with a lack of authorship information (for example Wikipedia and Responsibility, and Wikipedia Risks [CACM]). Since knol is not yet open to the public, I have yet to see it in actual operation, and many important details are currently unknown (to me, anyway). But based on the information available so far, it appears to avoid the aspects of Wikipedia that I consider to be so problematic and undermining. Wikipedia will still no doubt have its place. But if Google is able to grow knol successfully, I agree that it is likely to become a primary Internet resource for authoritative information of all kinds. As with so much else on the Net, time will tell. --Lauren-- Update (December 16, 2007): I've been asked why I didn't mention the Citizendium project in the discussion above. It's really a very different ball of wax. While Citizendium does attribute authors and editors, a concept I obviously support, it still (as I understand it) continues to allow uncontrolled changes of most items at any time by anyone in their pool of accepted contributors (though particular versions may be flagged as "approved," further changes by any contributors to additional versions can apparently continue). This appears very different from the Google knol model where comments and discussion of items are welcome, but the foundational essays themselves are controlled by the original author -- especially important for authors who have demonstrated expertise in that specific field. This is a world of difference, and personally I much prefer the reported knol methodology. One other thing. Knol will allow authors to potentially receive some financial compensation for their work through ads if they wish. I think it's about time that we recognize a basic fact -- not everyone has the resources to write everything for free on the Net, and while I prefer that authors be paid on a direct basis for their work, the knol methodology at least gives them a shot at getting something in return to help pay the rent. --LW-- |
|
Greetings. Since the controversy was touched off last weekend regarding Rogers of Canada's testing of a system to modify the content of Internet traffic by inserting their own messages into Web data streams, Rogers has been busy at damage control. Their take on all this, in both public statements and in replies to outraged customers that have been forwarded to me, is straightforward in an Orwellian Newspeak sort of way. Rogers' view appears to be that it's perfectly acceptable for them to insert additional content of their own choosing into the private communications between Web services and those services' users on a widespread basis, and that they don't consider their actions to be modifying content at all -- despite the fact that the look of received pages is changed in major ways, such as by pushing significant parts of the original Web pages to the bottom of the display screen or off the displayed area entirely, adding logos for competitors onto the original sites' pages, and so on. By Rogers' sort of twisted interpretation, if the postal service steamed open letters, stuffed in their own announcements, promotional and third party materials, resealed the envelopes, and then delivered them, this wouldn't be modifying or tampering with the mail. Insanity. The same sort of Bizarro World party line is echoed over at the "unlimited potential of In-Browser Marketing" PerfTech equipment site, where text (reportedly added after this controversy began, I'm told) also takes the view that splicing all manner of ISP-provided content into users' Web communications isn't "modifying content" at all. It isn't even necessary to get into the technical intricacies of the Network Neutrality debate for most Internet users to intuitively recognize that the most basic function of an ISP is to completely and accurately pass Web services' data to users, and vice versa -- no more, no less. The sort of Felliniesque content modifications reasoning that ISPs appear poised to widely inflict onto the Internet is an affront to the intelligence of their subscribers, and a gross interference with communications (from both business and personal standpoints) that cannot be tolerated. Even Big Brother would have had trouble getting people to buy into such unadulterated ISP-based nonsense, whether it's in 1984 or the early 21st century. ISPs continue to unwittingly provide the best examples of why Network Neutrality is so important. Thanks, guys! --Lauren-- |
|
Greetings. This message is basically a heads-up warning. I have discovered a serious and easily exploited security flaw in the operations of a major commercial Web services provider, which exposes the street address and/or billing address information for (apparently) a very large proportion of U.S. landline phone numbers, even if those numbers are unlisted. While such "reverse lookups" for listed numbers are common, unlisted number information is supposedly held to the highest security standards of telephone company customer premises information -- though third party mining of this data has been of increasing concern. How this unlisted number data has found its way into this publicly accessible database is a very interesting question indeed. Most people must pay extra for unlisted numbers, and often have them for security reasons. With numbers so widely exposed by calling number identification systems (CNID) and in the course of routine business transactions, the easy availability of the addresses associated with these unlisted numbers is a very serious matter. I am still attempting to reach responsible parties at the firm involved. I will not expose the technique for obtaining these addresses here and now for obvious reasons, but I will consider providing more details upon request to bona fide security experts and media -- under appropriate confidentiality guidelines to protect this data until the breach has been closed. More later. --Lauren-- Blog Update (December 20, 2007): Psst! Wanna Know the Street Address for an Unlisted Number? |
|
Greetings. If you need demonstrative proof of the low level of esteem to which ISPs seem to have fallen with their customers, you'd need only look at some of the responses to my posting yesterday Toward Pervasive Internet Encryption: Unshackling the Self-Signed Certificate. A number of persons wrote to express concerns that my proposal suggesting the increased use of self-signed certificates for routine Web browsing would be vulnerable to "man in the middle" (MITM) attacks by ISPs via security certificate manipulation and substitution. I had noted the presence of MITM risk issues in a previous posting, but a few more words on this topic are in order. While such an abhorrent behavior by ISPs is certainly technically possible, I believe it would be a mistake to underestimate the gravity of offense that would be involved with an ISP actually tampering with -- that is, forging or substituting -- security certificates of any kind. The reason that self-signed certificates could be immediately useful is that we need to start bootstrapping rapidly toward the routine use of encrypted Web communications. Some ISPs are taking the position that unencrypted communications are fair game for them to mine and alter as they see fit. The use of authority-signed certificates is of course preferable whenever possible. But the use of self-signed certificates for now -- even with their limitations, and until an improved certificate regime is freely available -- would still at least serve to put ISPs on notice that these data streams are encrypted and off-limits. Any ISP that was caught playing MITM certificate substitution games on encrypted data streams without explicit authorization would certainly be thoroughly pilloried and, to use the vernacular, utterly screwed in the court of public opinion -- and quite possibly be guilty of a criminal offense as well. I doubt that even the potentially lucrative revenue streams that could be generated by imposing themselves into users' Web communications would be enough to entice even the most aggressive ISPs into taking such a risk. But if they did anyway, the negative impacts on their businesses, and perhaps on their officials personally as well, would be, as Darth Vader would say, "Impressive. Most impressive." --Lauren-- |
|
Greetings. In http: Must Die! (and The Encryption Solution), I suggested an accelerated move toward the routine use of encrypted TLS/https: instead of unencrypted http: for Web communications. An issue that cannot be ignored in this regard is the cost and logistics of server security certificates that are natively recognized by popular Web browsers. Certificates are required to enable TLS encryption in these environments, of course. And while the marketplace for commercial certs is far more competitive now than it was just a few years ago, the cost and hassle factors associated with their purchase and renewal are very relevant, especially for larger sites with many operational server names and systems. What isn't widely understood outside of the technical community is that "self-signed" certificates, which can be generated for free by anyone (and with essentially arbitrary expiration dates) can enable these cryptographic systems in a manner very similar to commercial certs. What self-signed certs typically won't provide is the same "web of trust" confirmation (via a widely recognized certificate authority) for the identity of a given site. However, in a vast number of applications where absolute identity confirmation is not required (particularly when commerce is not involved), self-signed certificates are quite adequate. Yes, as I alluded to in my previous blog posting, there are man-in-the-middle attack issues associated with this approach, but in the context of many routine communications I don't feel that this is as high a priority concern as is getting some level of crypto going as soon as possible. Given their significant capabilities, why then are self-signed certs primarily employed within organizations, but comparatively rarely for servers used by the public at large, even where identity confirmation is not a major issue? A primary reason is that most Web browsers will present a rather alarming and somewhat confusing (for the typical user) alert as part of a self-signed certificate acceptance query dialogue. This tends to scare off many people unnecessarily, and makes self-signed certificate use in public contexts significantly problematic. Security purists may bristle at what I'm going to say next, but so be it. I believe that we should strongly consider something of a paradigm shift in the manner of browsers' handling of self-signed certificates, at the user's option. When a browser user reaches a site with a self-signed certificate, they would be presented with a dialogue similar to that now displayed, but with additional, clear, explanatory text regarding self-signed certificates and their capabilities/limitations. The user would also be offered the opportunity to not only accept this particular cert, but also to optionally accept future self-signed certs without additional dialogues (this option could also be enabled or disabled via browser preference settings). If the user declined this option, the browser would continue to treat self-signed certs in the traditional manner. If the option were accepted, future self-signed certs would not trigger the query dialogue. In either case, the use of a self-signed certificate would ideally cause the appearance throughout that session of an appropriate unobtrusive but clearly visible "self-signed cert" notification message or icon. I would also recommend that the browser URL address bar change to a unique color (e.g. light blue or some other acceptable choice) to indicate a self-signed certificate in use. There are obviously significant security ramifications to this proposal to be carefully analyzed, and a range of variations in the ways that something along these lines might be implemented. But I hope that this discussion helps to stimulate explorations regarding the possible desirability and practicality of much larger scale use of self-signed certificates on the Internet, particularly to encourage the transition of routine Web browsing to an encrypted environment. --Lauren-- |
|
It's been fun http:, but a man's gotta move on and there's no place for you on the back of my bike anymore. You were fun once but you're a drag now, and I just can't trust you anymore. It's not your fault but that's the way it is. Sorry, kid. Hey, https:! C'mon over here! Greetings. Sometimes you just have to bite the bullet when it comes to significant technological changes, and I believe that such a time has come for the basic http: unencrypted Web protocol. When we first started discussing Network Neutrality some years ago, we mostly talked in terms of trying to make sure that data streams would be handled in a fair and nondiscriminatory manner. Then with the Comcast BitTorrent case, it became clearer that it was appropriate to worry about whether underlying protocols might be manipulated by ISPs, resulting in delays or outright blocking. But now it's increasingly obvious that we're dealing with a triple-whammy, with ISPs apparently gearing up to treat our data like a 1960s draft board physical. That is (to quote Arlo Guthrie's Alice's Restaurant): "... injected, inspected, detected, infected, neglected and selected." More specifically, as noted in Google Hijacked -- Major ISP to Intercept and Modify Web Pages and ISPs Spying On and Modifying Web Traffic, ISPs are increasingly taking the stance that our data is subject to ISP-based manipulation of all sorts. We're not talking about just traffic shaping -- though that's problematic enough in many cases. We're now looking at outright alteration of traffic contents -- the very payload of our Internet communications. ISPs have argued that such techniques allow for transparent removal of viruses, pop-ups, and so on. But now, feeling empowered by the capabilities of new TCP/IP mangling machines, the situation seems poised for consumers and businesses -- except perhaps those able to pay significant premiums -- to be relegated to serf (no pun intended) status in the ISP kingdoms. While public policy and legislative changes may eventually address some of these issues, there's something that we can do right now to start assuring that we can control our own Internet communications. That first, key action is to begin phasing out, as rapidly as possible and in as many application contexts as practicable, the use of unencrypted http: Web communications, and move rapidly to the routine use of TLS/https: whenever possible. This is of course but an initial step in a rather long path toward pervasive Internet encryption, but it would be an immensely important one. TLS is not a total panacea by any means. In the absence of prearranged user security certificates, TLS is still vulnerable to man-in-the-middle attacks, but any entity attempting to exploit that approach would likely find themselves in significant legal difficulty in short order. Also, while TLS/https: would normally deprive ISPs -- or other intermediaries along the communications path -- of the ability to observe or modify data traffic contents, various transactional information, such as which Web sites subscribers were visiting (or at least which IP addresses), would still be available to ISPs (in the absence of encrypted proxy systems). Another potential issue is the additional computational cost associated with setting up and maintaining TLS communication paths, which could become significant for busy server sites. However, thanks to system speed improvements and a choice of encryption algorithms, the additional overhead, while not trivial, is likely to at least be manageable. The associated security and privacy benefits make this transition essentially a no-brainer from a cost/benefit standpoint -- at least if we're really concerned about maintaining the integrity of the carefully crafted Web experience that we present to users. We've gotten a good run from http:, but all good things come to an end. A graceful retirement for virtually all unencrypted Web communications, and a brisk move to routine TLS/https: use, are both honorable and justified -- and practical now. Let's ride. --Lauren-- Technical Addendum: Some early feedback to this posting took me to task for using the term "SSL" rather than "TLS" in conjunction with my call for encryption. OK, ya' got me, TLS is the correct term these days for current systems. I admit it, I'm sometimes guilty of referring to both protocols as SSL in my non-technical, general Internet audience writings. Among the Internet user population at large the term SSL is still more recognized, from a functional standpoint both SSL and TLS are extremely similar, and they both are intertwined historically. However, I'm properly chastised, have changed the occurrences of SSL to TLS above in the main posting, and will avoid this lapse in the future. Secondly, it's been noted that a significant holdup to https: implementations in some key environments has been the traditional requirement for a separate IP address when using SSL/TLS, rendering server virtual hosts unusable. However, RFCs 2817, and 4366 (superseding RFC 3546) address this issue via suitable extensions, and various relevant implementations already exist, though there's more work to do. I didn't say that a transition to a fully encrypted Web environment could happen overnight. But all of the basic foundational pieces that we need to do so -- with suitable effort -- are already pretty much in place. |
|
Blog Update (January 6, 2008): Would You Know if Your ISP Tampered With Your Web Pages? Blog Update (December 30, 2007): Harbinger of 2008: ISPs Plow Forward with Internet Intrusion Plans Blog Update (December 14, 2007): Rogers Replies re Web Ambushing: White is Black, Up is Down, Ignorance is Strength
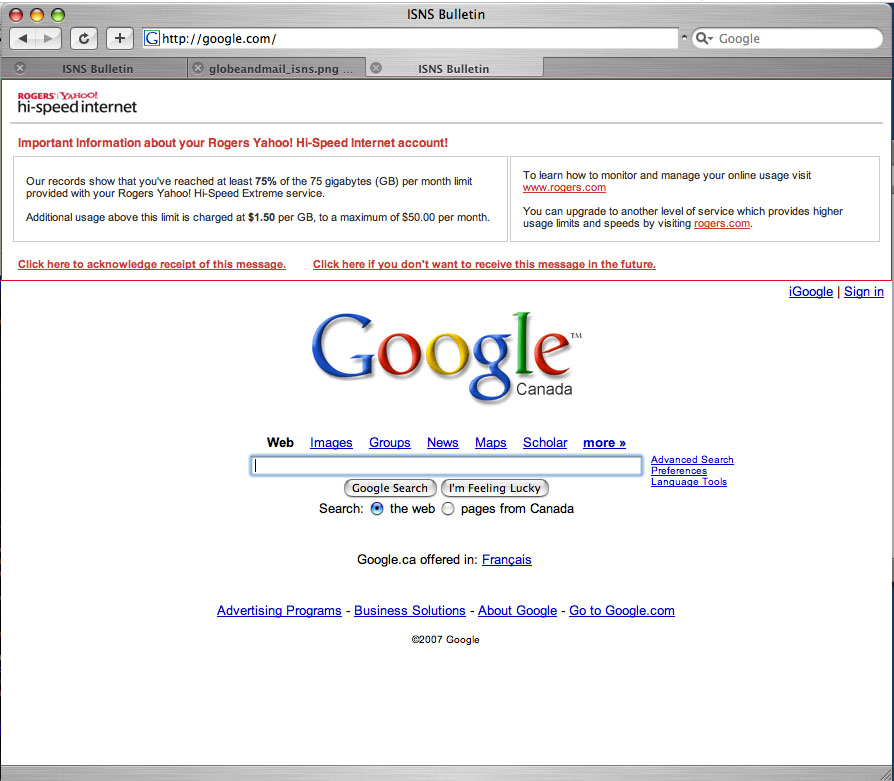
Greetings. Please observe closely the image to your left, showing the home page for Google Canada (click the image for a full-sized, full-resolution version). Does anything seem a bit odd about the normally clean and pristine Google front door? What the blazes is all that ISP-related verbiage taking up the top third of the page? Why would Google ever give an ISP permission to muddy up Google's public face that way? Well, as you've probably already guessed, Google didn't give this ISP any such permission. The ISP simply decided to modify Google on their own, demonstrating a real world example of ISPs Spying On and Modifying Web Traffic that I was discussing yesterday. Just brought to my attention today by a concerned reader who chose Google for his example, what you're looking at is reportedly an ongoing test by Rogers in Canada, scheduled for deployment to Rogers Internet customers next quarter. In case you're curious, "ISNS" on the test Google interception page apparently stands for Internet Subscriber Notification System. For the morbidly curious, here's the javascript and associated code that enables this procedure, which can presumably be applied to any http: (unencrypted) traffic. While Rogers' current planned use for this Deep Packet Inspection (DPI) and modification system (reportedly manufactured by "In-Browser Marketing" firm "PerfTech") is for account status messages, it's obvious that commercial ISP content and ads (beyond the ISP logos already displayed) would be trivial to introduce through this mechanism. By the way, PerfTech is even using Google for one of its linked promotional examples on the PerfTech home page. I wonder if they bothered to ask Google's permission for that? Anyway, the fact that there's an opt-out present for future account status messages on the Rogers page insertions hardly changes the extremely problematic and network neutrality unfriendly aspects of such situations, as I noted in yesterday's blog item. Question: Will Web service providers such as Google and many others, who have spent vast resources in both talent and treasure creating and maintaining their services' appearances and quality, be willing to stand still while any ISP intercepts and modifies their traffic in such a manner? I can't say for sure of course, but I suspect that a likely reaction might be discerned by paraphrasing Bugs Bunny: "Eh, he don't know them very well, do he?" --Lauren-- Blog Update (January 6, 2008): Would You Know if Your ISP Tampered With Your Web Pages? Blog Update (December 30, 2007): Harbinger of 2008: ISPs Plow Forward with Internet Intrusion Plans Blog Update (December 14, 2007): Rogers Replies re Web Ambushing: White is Black, Up is Down, Ignorance is Strength |
|
Greetings. Over on the NNSquad (Network Neutrality Squad) mailing list, the topic has arisen of ISPs spying on Web traffic and using the derived data to insert their own ads into the user data stream. In my view, such behaviors by any conventional general purpose ISP with their paid subscribers is unacceptable, even when opt-outs of some sort are supposedly available (from the spying or just from the ads? -- Not clear!) This appears to represent a clear violation of basic network neutrality principles. A fairly new patent application demonstrates the depth of intrusion that has been contemplated for the associated enabling devices [emphasis added]: United States Patent 20070233857 (Application) It's important to note the vast difference between this sort of activity by a primary ISP, vs. ad insertions at Web sites that occur with the cooperation or at least the assent of the Web site operators. The latter category only affects users who choose to visit particular Web sites or use specific services (e.g. Gmail) as an affirmative (essentially, an opt-in) choice. While it's possible in some cases to argue the fine points of privacy issues related to ad serving systems in this class of environments, it's generally the case that these services are chosen voluntarily by users on a case-by-case basis. However, since ordinary "last mile" ISP circuits represent the only means of accessing the Internet for the vast majority of consumers and businesses, ISPs drafting their conventional paying customers on a default basis into pervasive traffic monitoring and modification regimes, are taking improper and unacceptable advantage of their gateway roles and are obviously behaving in a non-neutral and potentially highly abusive fashion. This sort of ISP behavior may arguably be more acceptable in some very specialized situations -- such as with WiFi access services provided without charge for example, but even then only with full and complete disclosure and ironclad privacy protections, with appropriate data destruction - expiration - anonymization guidelines for the collected transactional data. For ISPs providing conventional paid Internet access services -- even where such protections and guidelines are present -- these monitoring and traffic modification systems deployed in any form other than with affirmative customer "opt-in" cannot be condoned and should not be accepted by any Internet users. --Lauren-- |
|
Greetings. Washington is hot to trot on the concept of forcing massive invasive data retention by ISPs, telephone companies, and all manner of other services, in the interests we're told of fighting terrorism and crime. But what's demanded of ordinary citizens obviously doesn't count for the powers-that-be, even when it comes to matters of great import. First, we learned that the White House mysteriously lost vast numbers of e-mails that were mandated to be retained by law. Penalty so far? Zip. Now comes word that CIA videotaped some of their torture sessions, and then -- apparently after a few chuckles reviewing the vids -- destroyed them. CIA claims that the tapes were liquidated (but one wonders, are all copies really gone?) to avoid retaliation by adversaries who might identify the torturers if the tapes leaked. That's the party line. But the real reason for the purported elimination was obviously to help avoid the risk of successful criminal prosecutions for using interrogation techniques such as waterboarding, which have long been illegal under international agreements and U.S. military law. This isn't rocket science. These guys aren't idiots -- far from it. The only conceivable reason that such key evidence would be destroyed would be concerns about personally ending up in orange jumpsuits. Congress will probably end up giving the administration a pass on this, just as they have for pretty much everything else from the Bush gang. But as far as I'm concerned, a crook is a crook, whether they operate out of a back alley in the red light district, or from an office in Langley. Disgusting. --Lauren-- |
|
Greetings. Back in July when I inflicted upon the Net my Gilbert and Sullivan parody I Am the Very Model of a Modern Major Googler, these lyrics were included: But companies worth billions are between a rock and a hard place, I was reminded of these words very recently while reading a few of the responses to my recent commentary regarding Facebook, where I suggested that Facebook was treating users like nothing more than raw materials to be squeezed dry of every drop of potential profit. The rather disheartening attitude expressed by some of these responding e-mails could best be summarized as: What the hell do you expect? These are extremely valuable corporations. Why should they do anything other than maximize profits by any and all legal means possible? They don't have any responsibility to treat users as anything other than profit center fodder or to do anything that doesn't help their bottom lines. Better duck down -- the spit flying! And it doesn't portend at all well for the Internet if such a mercenary philosophy proves to dominate, given the immense information and transactional powers of the most popular Internet services. Does it have to be this way? No, but the balancing act can be a tightrope walk extraordinaire to be sure. Look at Google for example. There's been quite a bit of chuckling in some quarters whenever Google undertakes a project that seems not to have an immediate profit motive. Some stock analysts couldn't wait to pile on criticisms over Google's renewable energy efforts, for example -- seemingly ignoring the fact that Google indeed has serious interests in energy sector issues -- those gazillion (more or less) servers aren't running on happy thoughts alone. But putting the power bill aside, is there really anything so unspeakably awful about devoting some resources to efforts that don't necessarily pile gold bullion in the vault from day one? Similarly -- and no doubt I'm inviting more emotional retorts -- I simply don't sense in Google today the sort of utterly predatory attitude toward its users that does seem to pervade some other major Internet-related firms. This is not to say that I agree with all Google policies -- as regular readers of this blog know. But I believe it's safe to say that even many (or most) Google employees also don't necessarily agree with all of Google's policies. It seems clear from public statements that even the Google leadership feels internally conflicted at times regarding some of their own policy issues -- torn between fiduciary considerations and the real world complexities of operations in a politically-charged international arena. Such conflicts and associated nuanced views are actually a very healthy sign. There are few more reliable indicators of potential problems in an organization than blind faith that never questions policies. It's not necessary -- and in fact can be counterproductive to openness of internal discussions -- that the details of such debates and deliberations be visible to the outside world. But the fact that vibrant policy debates are taking place within organizations such as Google is a factor that must not be ignored, even in cases where one disagrees with the outcome of those deliberations. Ultimately, whether we're talking about Google or Facebook, it's users themselves who carry most of the high-value cards, for as I've noted before, Internet users can change their service allegiances essentially at the click of a mouse. Our collective interests are best served by not belittling or devaluing the efforts of firms that try to move beyond the bottom line, especially in their treatment of their customers and users. Or to quote Charles Dickens' Ghost of Jacob Marley: "Business! Mankind was my business. The common welfare was my business; charity, mercy, forbearance, and benevolence, were, all, my business. The dealings of my trade were but a drop of water in the comprehensive ocean of my business!" And so it goes, even today. Especially today. --Lauren-- |
|
Greetings. If the publishing industry's Automated Content Access Protocol (ACAP) project has been flying under your radar during its gestation period of the last year or so, don't feel too bad. Unless you're a serious follower of the complex dance between publishers and search engines, you probably didn't even know that the publishing industry wants to "extend" the venerable Robots Exclusion Protocol (robots.txt) with a complex new system to control search engines' access to and use of content. Here's an excellent new Associated Press article regarding the ACAP announcement (AP is a member of the ACAP project). Very briefly, ACAP defines a detailed new system for sites to to tell search engines what they may or may not index, and adds mechanisms to specify that certain materials may only be held in indexes for limited periods of time, or only displayed in thumbnail form, or other restrictions -- conceivably such as "don't index this material unless you've paid us first." The official ACAP line is that this system will encourage the availability of more materials on the Internet. In fact, it is generally acknowledged that robots.txt is a relatively simplistic mechanism, and various new search enhancement systems (such as Sitemaps (originated by Google in 2005) have indeed been evolving. While ACAP claims broad participation by the publishing industry (true enough), its assertion that major search engines are on board is somewhat problematic, given that none of the search engine biggies that would spring immediately to mind have signed up to date, or agreed to abide by ACAP specifications when crawling sites (they all basically say that they are evaluating the standard). I'm certainly in favor of publishers being able to control their content. On the other hand, my general view has long been that you shouldn't put materials online (when not protected by explicit user access controls such as passwords or certificate-based control mechanisms) unless you're willing for the public to access it in a reasonably open manner. This philosophy doesn't mean that you're giving up your copyrights by placing information on the Web. But I would suggest that attempting to shift a complicated onus of responsibility for exactly how available materials may be handled by search engines, appears questionable and permeated with considerable risks to the Internet at large. Though ACAP is currently a voluntary standard, it might be assumed that future attempts will be made to give it some force of law and associated legal standing in court cases involving search engine use and display of indexed materials. The fundamental ACAP structure appears to be weighted in a manner that provides the bulk of potential benefits to the publishing entities and the greater part of risks to the search engines. One possible outcome of this skewing could be that search engines, concerned regarding litigation risks associated with not complying exactly with any given set of ACAP directives, might restrict their indexing of any involved sites in rather broad strokes. This could result in a dramatic decrease in available materials for the public, rather than the ACAP group's suggested increase. In essence, rather than the current framework where entities putting materials on the Web take responsibility for what they've placed online, the ACAP structure would appear to allow pretty much anything to be placed online with far fewer concerns by their publishers, who would presumably feel secure in the knowledge that it would be up to search engines to obey ACAP or face possible lawsuits and related actions. Boiled down to the bottom line, I can't help but sense that the intended shift in responsibility that appears to be associated with ACAP could lead to an entire new wave of litigation and possible information restrictions -- enriching lawyers to be sure -- but quite possibly being a significant negative development for Internet users in general. It's too early in the ACAP life cycle to make any truly definitive calls regarding the benefits, risks, or even basic viabilities of ACAP itself. But I believe that an "orange alert" is in order. ACAP is a potentially major development with possibly wide-ranging impacts on an exceedingly broad range of activities that are common on the Internet today. At the very least, we should all be watching events in this area with great care and with considerable healthy skepticism. --Lauren-- |